میزان دادهای که در واحد زمان توسط یک دستگاه فیزیکی قابل ارسال یا دریافت باشد، معمولاً بر حسب بیت بر ثانیه (bps) اندازهگیری میشود.




Distance Vector یکی از الگوریتمهای مسیریابی است که در پروتکلهای مسیریابی شبکههای کامپیوتری برای تعیین بهترین مسیر به مقصد استفاده میشود. این الگوریتم بهطور خاص در پروتکلهای مسیریابی مانند RIP (Routing Information Protocol) بهکار میرود و به روترها این امکان را میدهد که اطلاعات مسیریابی خود را با دیگر روترها به اشتراک بگذارند. در این مقاله، به بررسی مفهوم Distance Vector، نحوه عملکرد آن، مزایا و معایب آن خواهیم پرداخت.
Distance Vector یک روش ساده برای مسیریابی است که در آن هر روتر اطلاعات خود را در مورد فاصله به مقاصد مختلف و همسایگان خود در قالب یک "Vector" ارسال میکند. در این روش، هر روتر برای رسیدن به مقصد از تعداد هاپها (Hops) بهعنوان معیار استفاده میکند و این مقدار را برای هر مقصد در جدول مسیریابی خود ثبت میکند.
Distance Vector یک الگوریتم مسیریابی است که در آن هر روتر جدول مسیریابی خود را بهطور دورهای با روترهای همسایه خود به اشتراک میگذارد. این جدول شامل اطلاعاتی مانند مقصد، تعداد هاپها به مقصد و آدرسهای روتر بعدی است که برای رسیدن به مقصد استفاده میشوند. در این الگوریتم، هر روتر اطلاعات را بهصورت یک بردار (Vector) به دیگر روترها ارسال میکند، بهطوریکه اطلاعات مربوط به مقصدهای مختلف بهصورت جداگانه و با استفاده از تعداد هاپها بهعنوان معیار ارسال میشود.
در واقع، در الگوریتم Distance Vector، هر روتر اطلاعات مسیریابی خود را به سایر روترهای همسایه ارسال میکند و بر اساس این اطلاعات، مسیر بهینه برای ارسال دادهها انتخاب میشود. این روش بهویژه در شبکههای کوچک و متوسط استفاده میشود، زیرا نیاز به حافظه و پردازش کمتری دارد.
عملکرد Distance Vector به این صورت است که هر روتر جدول مسیریابی خود را بهطور دورهای به روترهای همسایه ارسال میکند. در این جدولها، هر روتر اطلاعاتی در مورد مقصد و تعداد هاپها برای رسیدن به آن مقصد ذخیره میکند. مراحل عملکرد Distance Vector به شرح زیر است:
Distance Vector مزایای زیادی دارد که آن را به یک پروتکل مسیریابی ساده و محبوب تبدیل کرده است. برخی از این مزایا عبارتند از:
با وجود مزایای زیادی که Distance Vector دارد، این الگوریتم معایب خاص خود را نیز دارد که باید در نظر گرفته شوند. برخی از معایب آن عبارتند از:
الگوریتم Distance Vector در بسیاری از شبکهها و پروتکلها بهکار میرود. برخی از کاربردهای اصلی آن عبارتند از:
Distance Vector یک الگوریتم ساده و کارآمد برای مسیریابی دادهها در شبکههای کوچک و متوسط است. این الگوریتم با استفاده از تعداد هاپها بهعنوان معیار برای انتخاب مسیر، از روترها خواسته میشود تا بهطور خودکار جدولهای مسیریابی خود را بهروز کنند. در حالی که Distance Vector در شبکههای کوچک کارایی خوبی دارد، در شبکههای بزرگ و پیچیده محدودیتهایی دارد و ممکن است بهویژه در هنگام تغییرات توپولوژی مشکلاتی ایجاد کند. برای درک بهتر نحوه عملکرد Distance Vector و استفاده از آن در شبکههای مختلف، میتوانید به سایت saeidsafaei.ir مراجعه کنید.
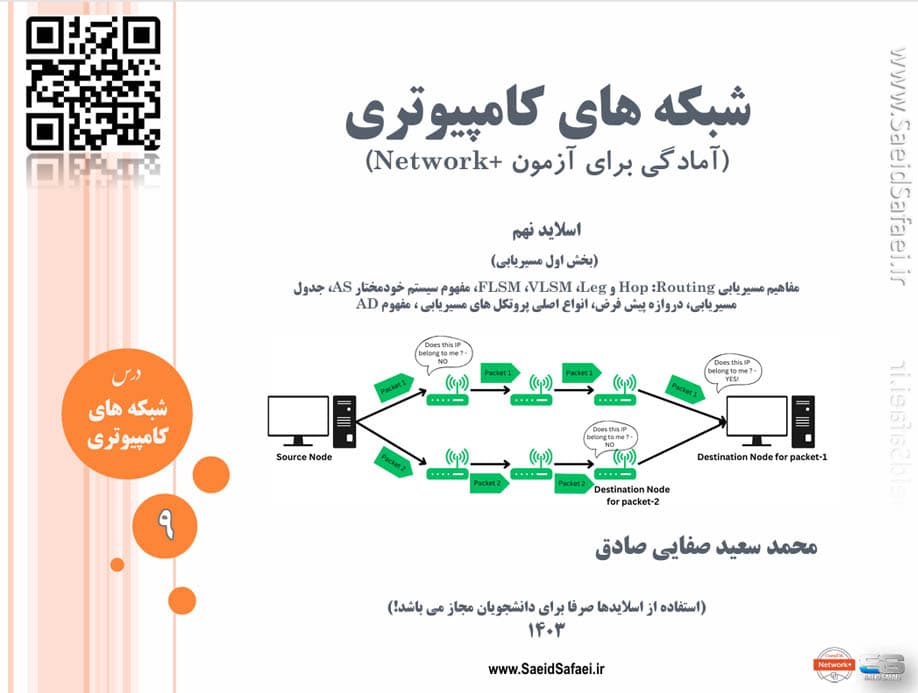
در این جلسه (بخش اول مسیریابی)، مفاهیم پایهای مسیریابی (Routing) مانند Hop، InterVLAN و Leg بررسی میشوند. سپس، تکنیکهای VLSM (Variable Length Subnet Mask) و FLSM (Fixed Length Subnet Mask) توضیح داده میشوند. همچنین، مفهوم سیستم خودمختار (AS) و اهمیت آن در مسیریابی، ساختار جدول مسیریابی و نقش دروازه پیشفرض بررسی خواهد شد. در نهایت، انواع کلاسهای پروتکلهای مسیریابی معرفی و ویژگیهای آنها مورد بحث قرار میگیرد. هدف این جلسه، درک اصول مسیریابی و نحوه مدیریت مسیرها در شبکههای پیچیده است.
میزان دادهای که در واحد زمان توسط یک دستگاه فیزیکی قابل ارسال یا دریافت باشد، معمولاً بر حسب بیت بر ثانیه (bps) اندازهگیری میشود.
تکرار به فرآیند اجرای دوباره یک دستور یا مجموعه دستورات گفته میشود. این واژه بیشتر در کنار حلقهها استفاده میشود.
سیگنالی که در آن اطلاعات به صورت گسسته و با دو سطح مشخص (0 و 1) منتقل میشود.
هایپراتوماسیون به استفاده از هوش مصنوعی، یادگیری ماشین و رباتیک برای خودکارسازی فرایندهای پیچیده و بهینهسازی کارهای تجاری اطلاق میشود.
سیگنالی که به صورت پیوسته تغییر میکند و معمولاً به صورت موج سینوسی نمایش داده میشود.
زندگی مصنوعی به مطالعه و شبیهسازی فرآیندهای زیستی گفته میشود که به ساخت موجودات مصنوعی شبیه به موجودات زنده میپردازد.
واحد پردازش گرافیکی است که برای انجام محاسبات پیچیده گرافیکی و پردازش دادههای بصری به کار میرود.
موقعیت هر رقم در یک عدد که ارزش آن رقم را تعیین میکند. این مفهوم در سیستمهای عددی با ارزش مکانی به کار میرود.
سازمانهای خودمختار غیرمتمرکز (DAO) به سازمانهایی اطلاق میشود که بدون نیاز به مدیریت متمرکز با استفاده از قراردادهای هوشمند عمل میکنند.
هرگونه تغییر فیزیکی که برای انتقال اطلاعات از یک نقطه به نقطه دیگر استفاده میشود. این تغییرات میتوانند الکتریکی، نوری یا صوتی باشند.
هوش مصنوعی (AI) به سیستمهایی اطلاق میشود که توانایی انجام کارهایی که نیاز به هوش انسانی دارند را دارند.
مجموعهای از دادهها است که به صورت ساختار یافته ذخیره شده و به راحتی میتوان به آنها دسترسی داشت.
محاسبات با عملکرد بالا به استفاده از قدرت پردازشی پیشرفته برای حل مسائل پیچیده و پردازش دادههای بسیار بزرگ اطلاق میشود.
یک پورت یا رابط که روتر برای اتصال به دیگر دستگاهها یا شبکهها از آن استفاده میکند.
پروتکلی که برای شبکههای سیسکو طراحی شده است و از معیارهای مختلف مانند پهنای باند و تأخیر برای انتخاب بهترین مسیر استفاده میکند.
بافت داده به مفهوم استفاده از دادهها از منابع مختلف در یک شبکه برای تسهیل دسترسی و تحلیل اطلاعات است.
تابع درونخطی تابعی است که کد آن به جای فراخوانی معمولی مستقیماً در محل فراخوانی قرار میگیرد، که معمولاً برای توابع ساده و کوتاه استفاده میشود.
هوش مصنوعی در مراقبتهای بهداشتی به استفاده از الگوریتمها و مدلهای هوش مصنوعی برای بهبود خدمات پزشکی و پیشبینی بیماریها اطلاق میشود.
حذف به معنای از بین بردن دادهها از ساختارهای دادهای مانند آرایهها یا لیستها است.
لایهای که ارتباطات بین دستگاهها را مدیریت میکند و تضمین میکند که دادهها به درستی به مقصد برسند.
روش تقسیمبندی ثابت زیربخشهای شبکه که در آن تمامی زیربخشها از اندازه یکسان برخوردارند.
پروتکلی برای ارتباطات شبکه که پایهگذار اینترنت و بسیاری از شبکههای محلی است.
انتزاع به پنهان کردن جزئیات پیچیده و تنها نشان دادن جنبههای ضروری یک شیء یا فرآیند گفته میشود.
فرآیندی که در آن روترها مسیرهای بهترین برای ارسال بستههای داده به مقصد را تعیین میکنند.
کلمه کلیدی const در زبانهای برنامهنویسی برای تعریف متغیرهایی استفاده میشود که مقدار آنها ثابت است و نمیتوان در طول اجرای برنامه تغییر داد.
عمق بازگشت به تعداد دفعاتی اطلاق میشود که یک تابع بازگشتی خود را فراخوانی میکند. هرچه عمق بازگشتی بیشتر باشد، خطر بروز stack overflow بیشتر خواهد بود.
محاسبات هولوگرافیک به استفاده از فناوریهای هولوگرام برای پردازش و تجزیه و تحلیل دادهها در فضای سهبعدی اشاره دارد.
دروازه منطقی NAND که عملیات معکوس دروازه AND را انجام میدهد.
شاخهای از هوش مصنوعی است که به سیستمها اجازه میدهد از دادهها یاد بگیرند و بدون برنامهنویسی خاص، بهبود یابند.
سیستمهای چندعاملی (MAS) به استفاده از چندین عامل مستقل برای انجام وظایف و حل مسائل مشترک اطلاق میشود.
یک مگابایت معادل 1024 کیلوبایت است و برای اندازهگیری فایلهای نسبتاً کوچک به کار میرود.
متغیر سراسری متغیری است که در خارج از توابع و بلوکهای کد تعریف میشود و در سراسر برنامه قابل دسترسی است.
دروازه منطقی AND که زمانی خروجی 1 میدهد که ورودیهای آن هر دو 1 باشند.
هوش مصنوعی توزیعشده به سیستمهایی اطلاق میشود که از چندین عامل هوش مصنوعی برای حل مسائل پیچیده بهطور همزمان استفاده میکنند.
یادگیری فدرال به روشی برای آموزش مدلهای یادگیری ماشین گفته میشود که دادهها در دستگاههای محلی باقی میمانند و تنها مدلهای آموزش دیده با یکدیگر به اشتراک گذاشته میشوند.
